- Categories:
- computer vision, neuroscience, technology
I’ve spent a little time with Caffe over the holiday break to try and understand how it might work in the context of real-time visualization/object recognition in more natural scenes/videos. Right now, I’ve implemented the following Deep Convolution Networks using the 1280×720 resolution webcamera on my 2014 Macbook Pro:
- VGG ILSVRC 2014 (16 Layers): 1000 ImageNet Object Categories (~ 7 FPS)
- VGG ILSVRC 2014 (19 Layers): 1000 Object Categories (~5 FPS)
- BVLC GoogLeNet: 1000 Object Categories (~ 24 FPS)
- Region-CNN ILSVRC 2013: 200 Object Categories (~ 22 FPS)
- BVLC Reference CaffeNet: 1000 Object Categories (~ 18 FPS)
- BVLC Reference CaffeNet (Fully Convolutional) 8×8: 1000 Object Categories (~12 FPS)
- BVLC Reference CaffeNet (Fully Convolutional) 34×17: 1000 Object Categories (~1 FPS)
- MIT Places-CNN Hybrid (Places + ImageNet): 971 Object Categories + 200 Scene Categories = 1171 Categories (~ 12 FPS)
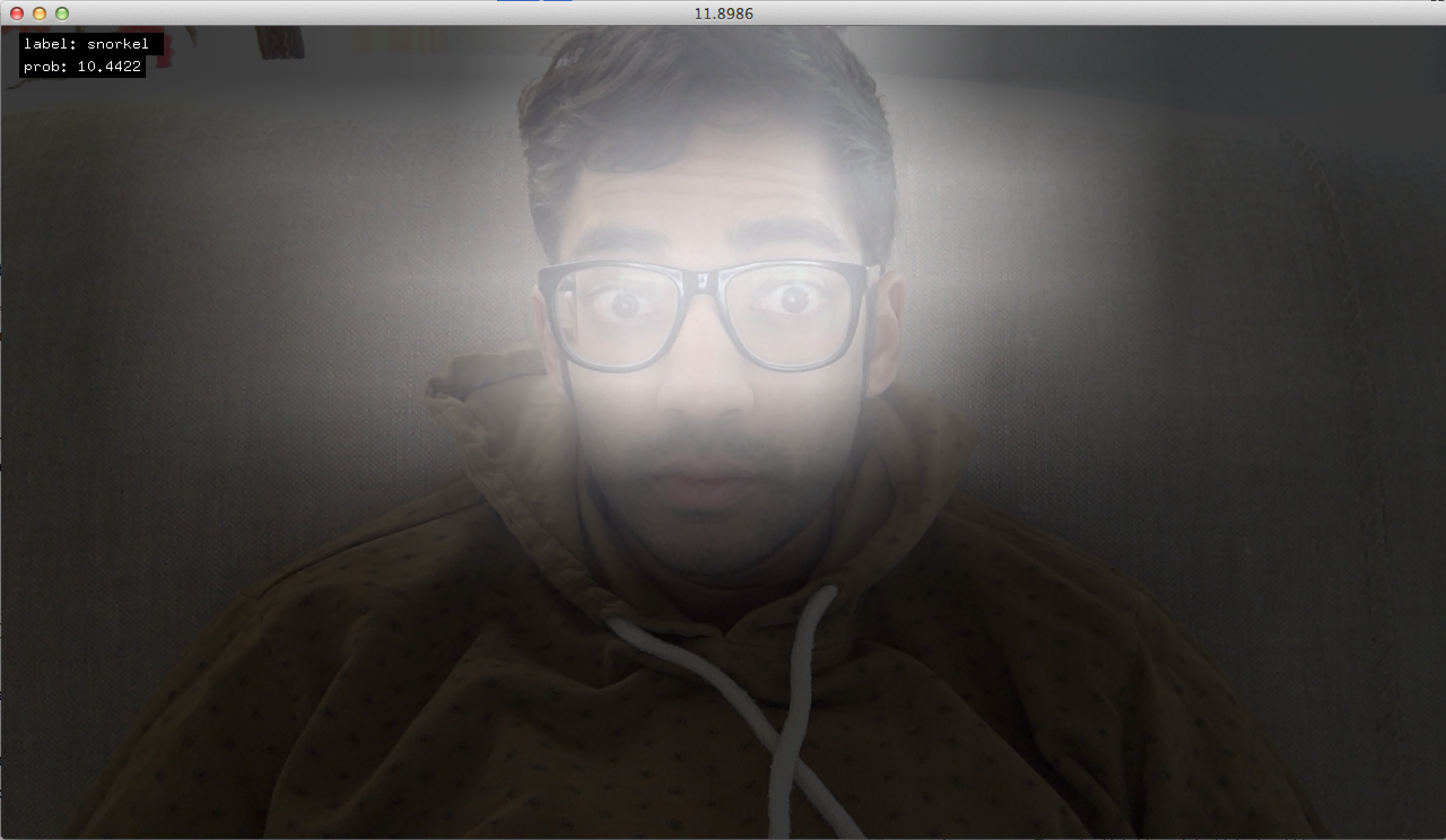
The above image depicts the output from an 8×8 grid detection showing brighter regions as higher probabilities of the class “snorkel” (automatically selected by the network from 1000 possible classes as the highest probability).
So far I have spent some time understanding how Caffe keeps each layer’s data during a forward/backward pass, and how the deeper layers could be “visualized” in a meaningful way.
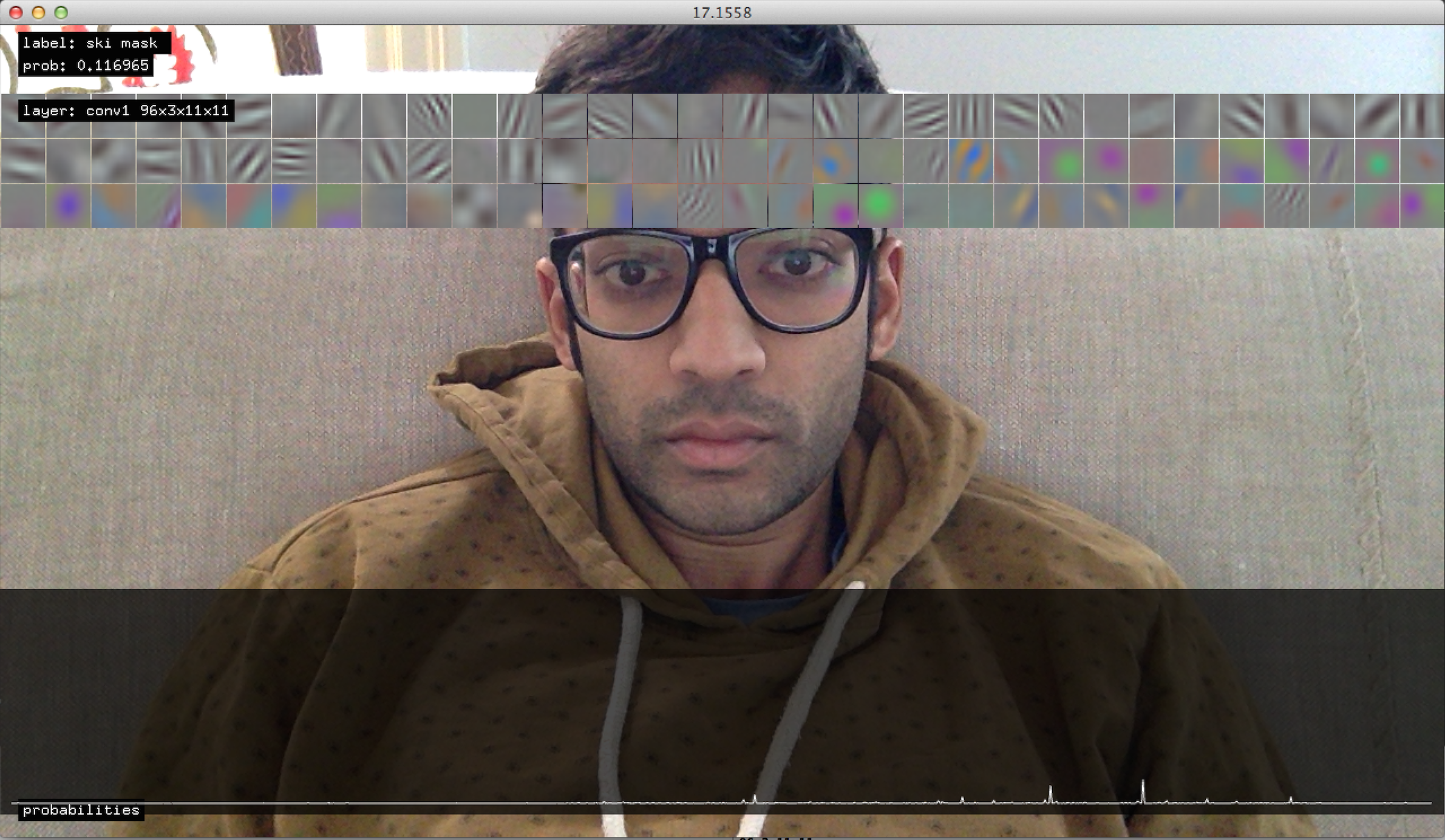
Past the 1st layer, the dimensions do not make sense for producing meaningful visualizations. However, recent work by Zeiler/Fergus, suggest the use of deconvnets as a potential solution for visualizing how an input image may produce a maximum response in a particular “neuron” . Their work attempts to reconstruct each layer of a convnet from the output. Another recent work by Simonyan et. al also attempt the problem. I haven’t yet wrapped my head around how that would work in this framework, but would really love to implement this soon. The following screenshots therefore only show the first 3 channels of a > 3 channel layer.
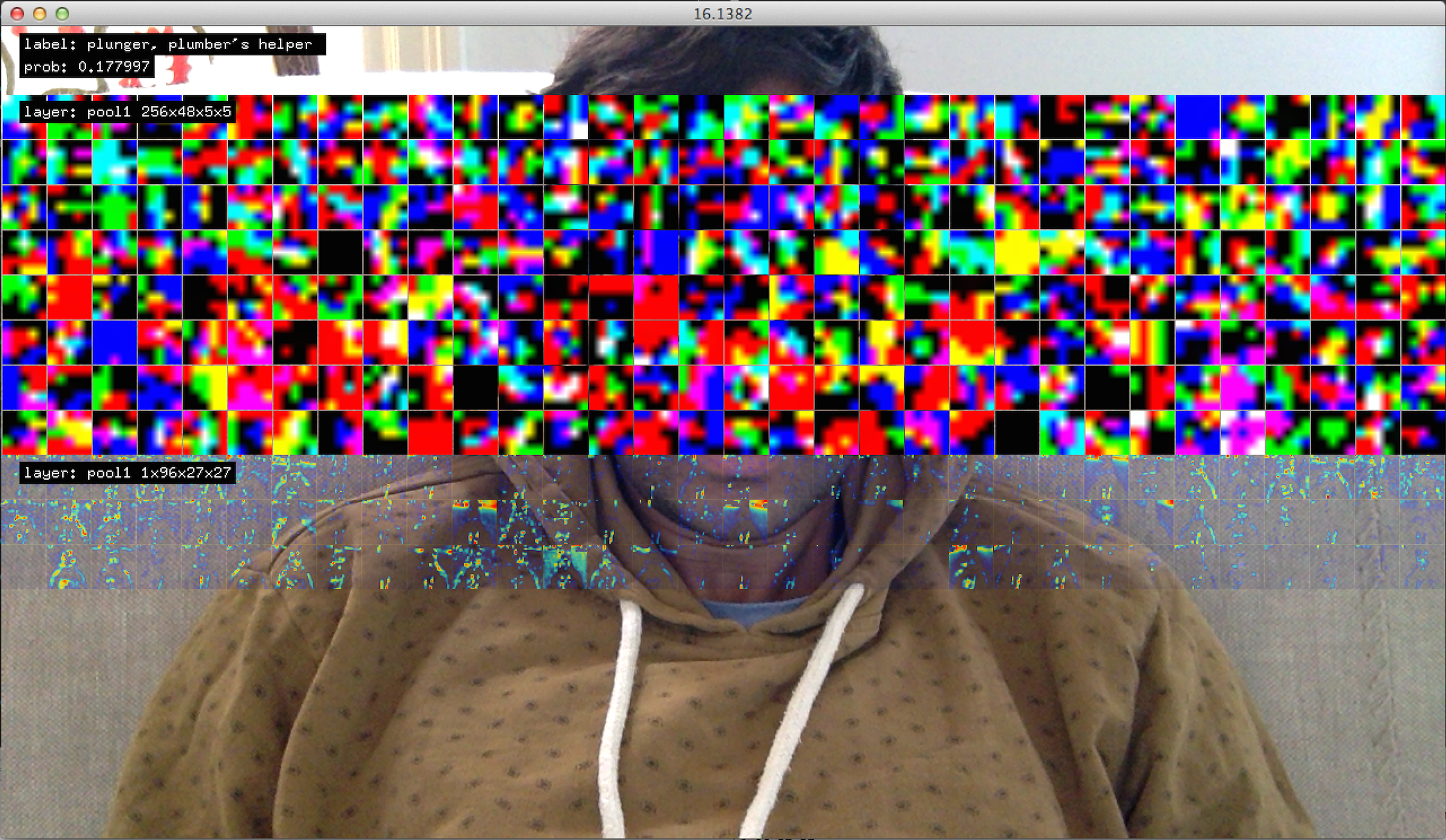
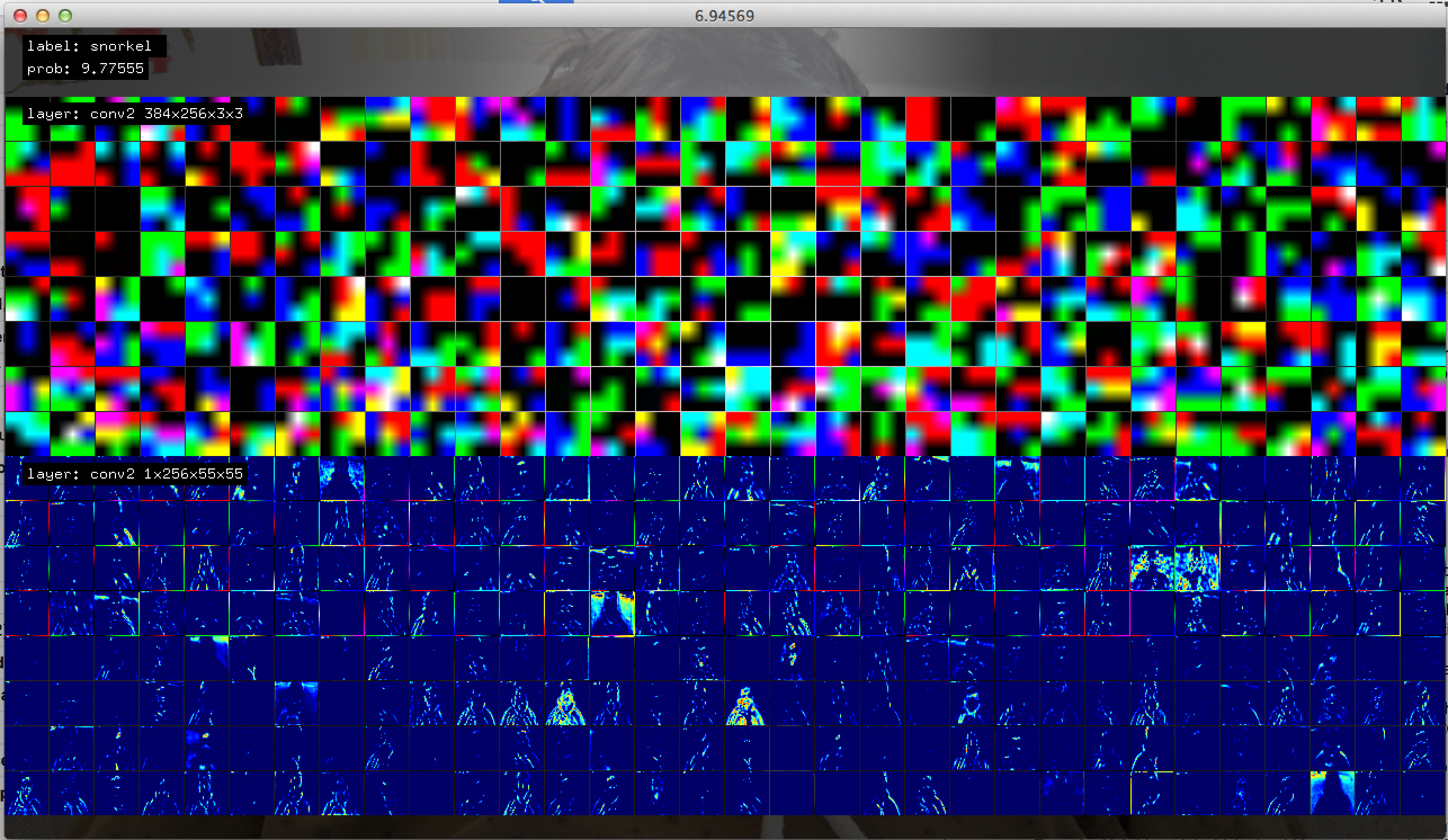
What the real-time implementation has taught me so far is that it is horrible at detecting objects in everyday scenes. Even the Hybrid model which should have some notion of both objects and scenes, though its not clear if these labels should even be within the same “hierarchy”. All of the models are very good (from my very simple tests using the webcam) when the scene is un-occluded, presented with only the object of focus, with fairly plain backgrounds. R-CNN’s focus seems to be aiding with this problem, though I have not implemented region proposals at the moment. Without such a constraint, often the network will end up jittering between a number of different possible object categories, though the scene itself does not seem to change very much. This may tell us something about how task, attention, or other known cognitive functions may interact with these networks.
Also, it is really fast.
I’ve also noticed that when I show my hand, it suggests with high probability (> 0.5) that it is a band-aid. Or that my face is “ski-goggles” or “sun-glasses”. These are fairly poor guesses, but understandable, considering what they have been trained on. I guess that may start to also tell us about the nature of the problem, and how a simple object class for an entire image depicting a scene is not necessarily how we should learn objects.
Lastly, it is quite easy to setup your own data, visualize the gradients, and get a sense of what is happening in real-time. The data is also agnostic to format, dimensionality, etc… I’d love to eventually try training something using this framework with other datasets such as sound, fMRI, and/or eye-movements.
Update 1: Code available here: ofxCaffe